Introduction
For the last couple of weeks, I have been discussing with my colleagues about
How can we improve the performance of some of our data access?
I will give you some background about the system so that we know our base tenets throughout this blog.
Let’s say the system stores the structured data in a database (Amazon DynamoDB) and unstructured data blob in some blobstore (Amazon S3). And, we want to improve the data access latency for both data stores as they provide sub-10ms latency for GET operations. What we are looking for is to reduce the GET operation latency to microseconds. But, as we all know, distributed systems always have trade-offs, so what are we willing to let go? Let’s say our system is read-heavy so we can probably compromise on the PUT operation latency. Now, what about the consistency model we want to follow? Let’s say we have both types of data, one that needs strong consistency and one that is fine with eventual consistency. We need to figure out the solution for both.
The first thing that pops into my mind when I look at the above requirements is
Can we use any Distributed Cache to cache the data?.
Distributed caching provides a way to store and retrieve frequently accessed data in a manner that drastically reduces access time and minimizes load on your backend databases.
In this blog of our Distributed Cache Series, we’ll explore Redis, one of the most popular and powerful distributed caching solutions available today. Redis isn’t just a simple cache; it’s a versatile in-memory data structure store that offers rich features, including support for various data types, persistence, and high availability. We’ll dive into how Redis works, how to leverage it for optimal caching strategies, and some best practices to ensure your caching layer scales with your application. We will also discuss various trade-offs it brings to the equation and its limitations. And answer the most important question, what problem it can and can’t solve.
We are not gonna discuss its security model and features in this blog as those are not relevant to this conversation. For security information, you can follow the reference [1].
High-Level Architecture
Redis Sentinel
Redis Sentinel [2] is a distributed system in itself, running as a separate process in parallel to the Redis server. It provides node monitoring, notification, automatic failover, master discovery, and election, and acts as a client configuration provider or service discovery. Multiple sentinel processes cooperate to detect and agree on failures, which lowers the probability of false positives but doesn’t completely eliminate the possibility. Also, having multiple processes running in parallel helps reduce the possibility of sentinel becoming an SPOF (Single Point of Failure). In short, it works as an Orchestrator to provide high availability to Redis.
Sentinel uses the concept of Quorum, which is a fixed set of sentinels that need to agree about the fact that the master is not reachable, to really mark the master as failing, and eventually start a failover procedure if possible. However, to perform the failover, one of the sentinel will be elected leader and authorized to proceed with the failover. And, this election and authorization is done by the voting among sentinels where majority (⌈n/2⌉, where n is the total number of sentinels) have to agree. Having at least the majority makes sure that failover is not done when the majority of sentinels are not reachable, making it impossible to failover in a split-brain partition situation where partition doesn’t have majority.
Quorum Election - Case I - Master Down
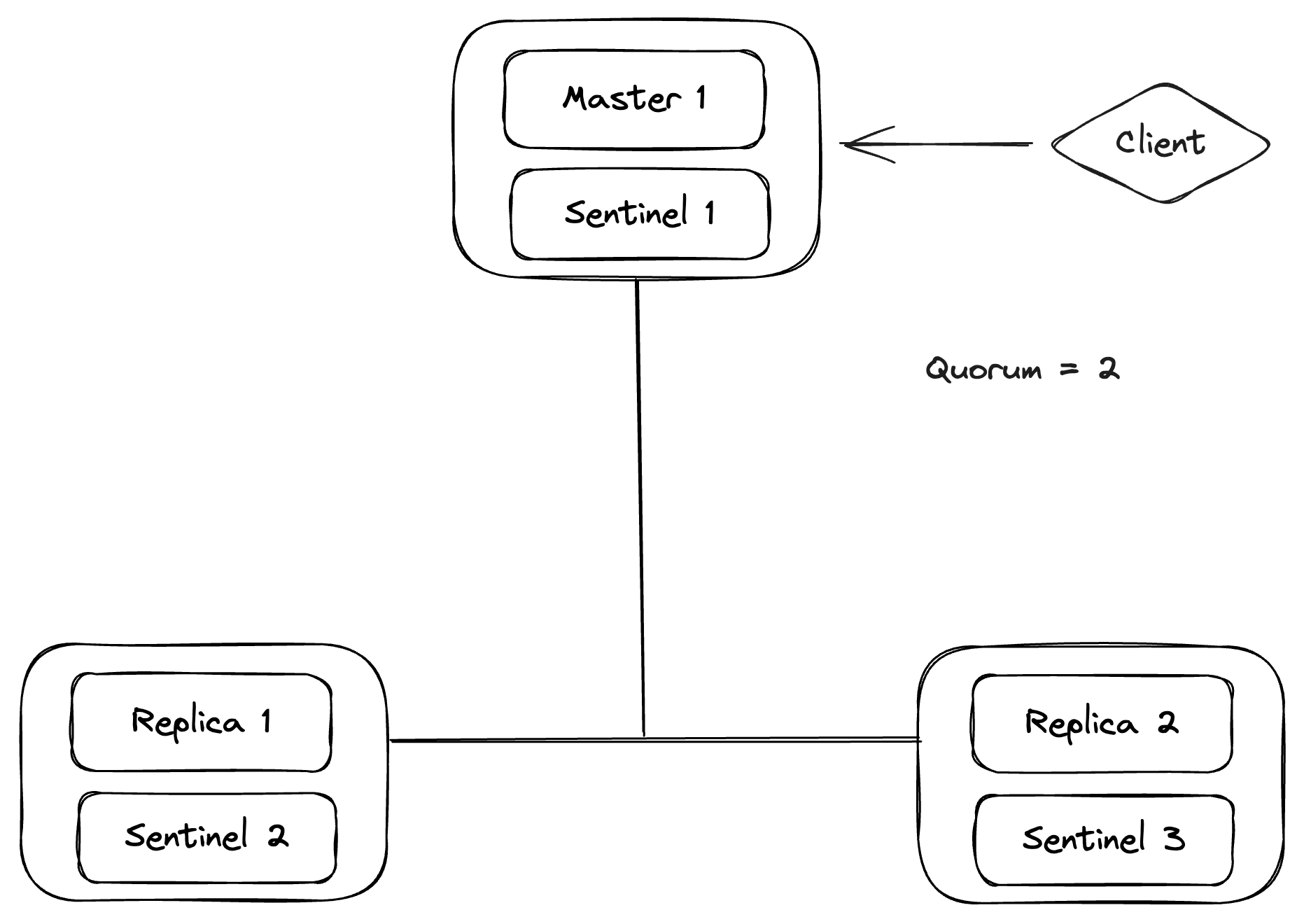
Let’s take a simple case where we have 3 Redis instances, running 3 sentinels, 1 master, and 2 replicas, with a quorum configuration set to 2.
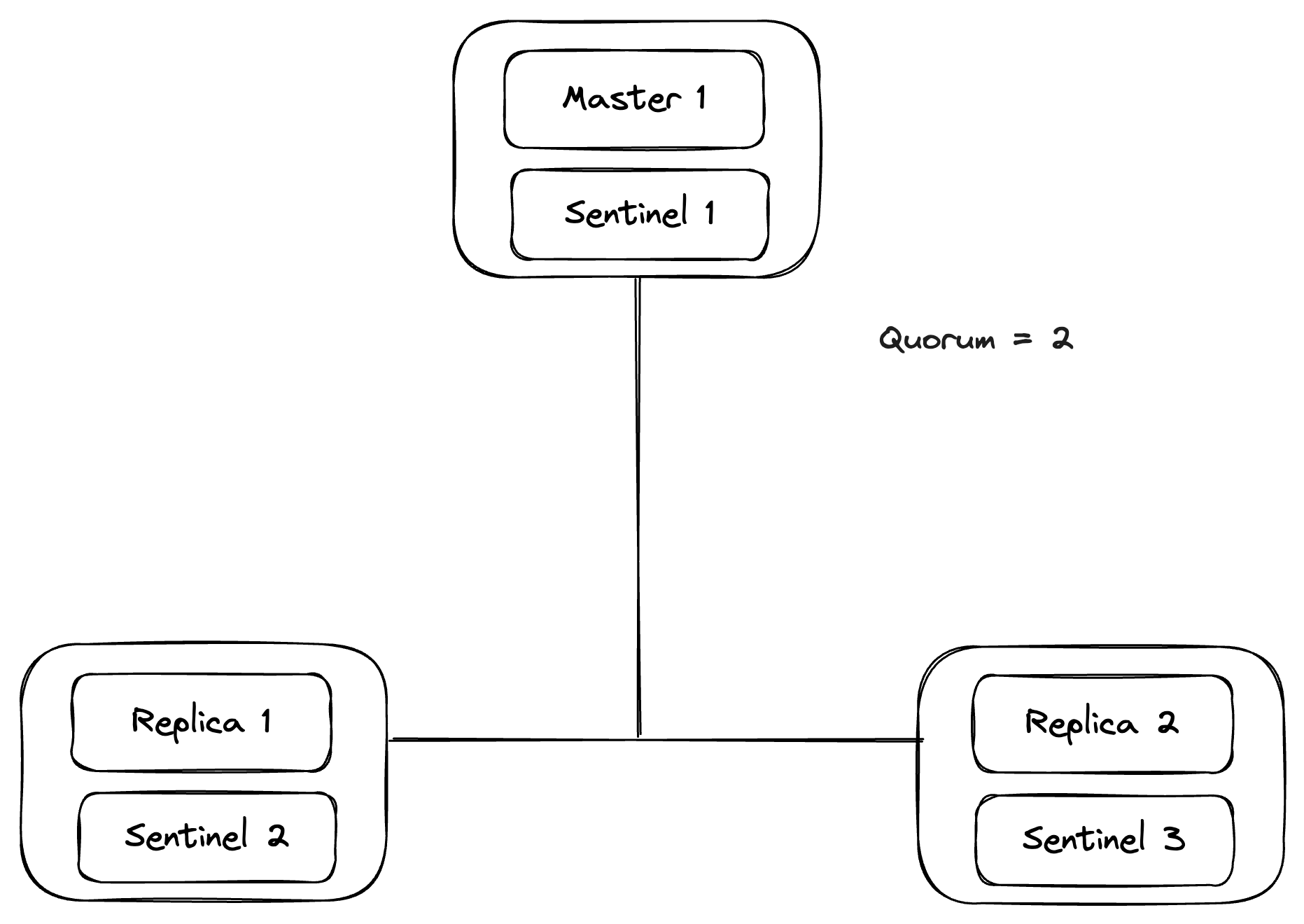
Let’s say Master 1 fails or is not reachable. Then, Sentinel 1/2/3 will discover that Master 1 is down and agree on its failure. As the quorum config is set to 2 only, we only need 2 sentinel nodes to agree on the Master 1 being down and mark it as failing.
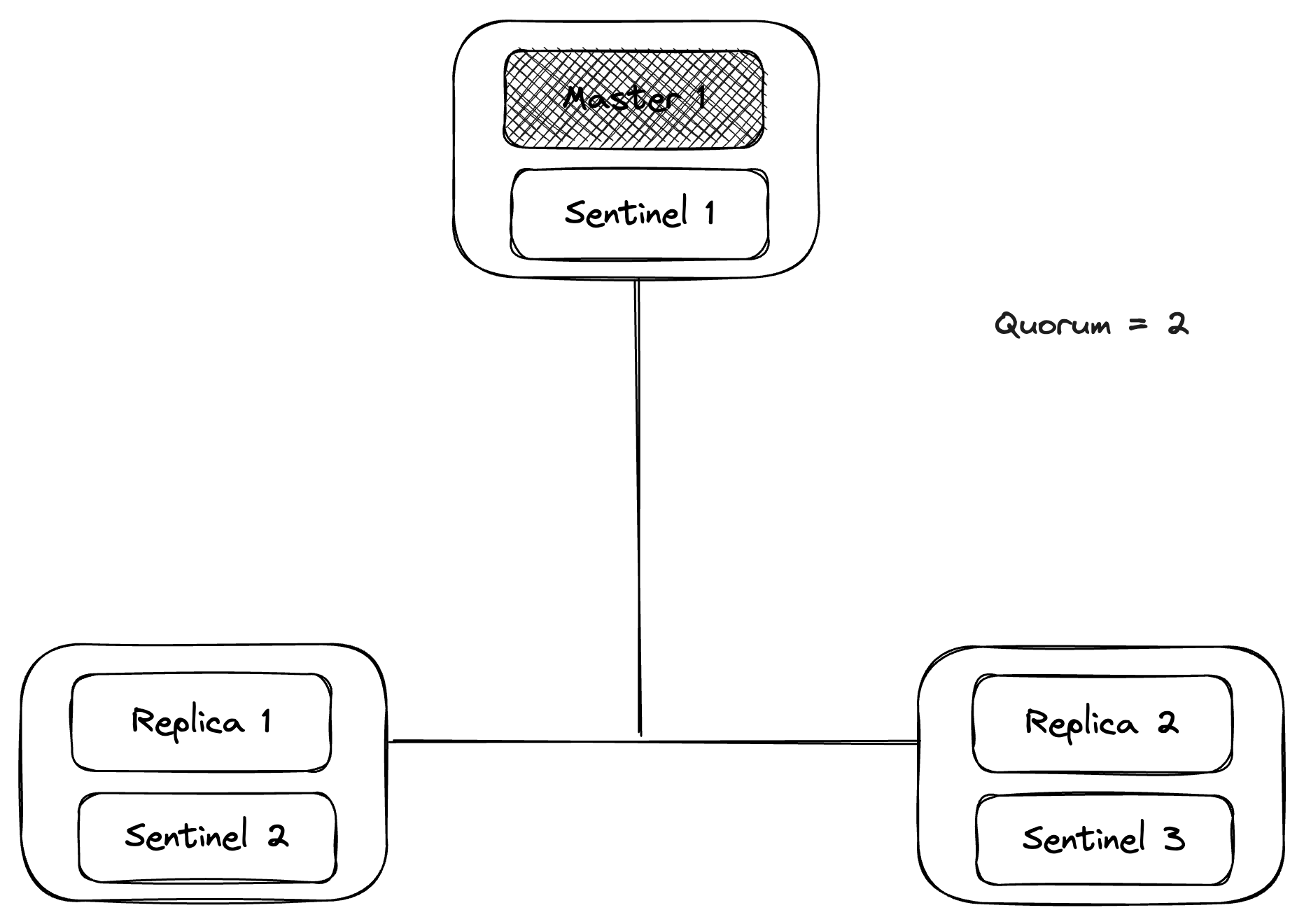
After that, one of the three sentinels will be elected as leader by running an election among all reachable sentinels. A sentinel will be elected as leader only when the majority of the total sentinels in the cluster agree on it. After that, the elected sentinel will flip one of the replicas with the most recent commit (the sentinel tries its best to identify this replica, not always possible) to a new master and update the sentinel configuration.
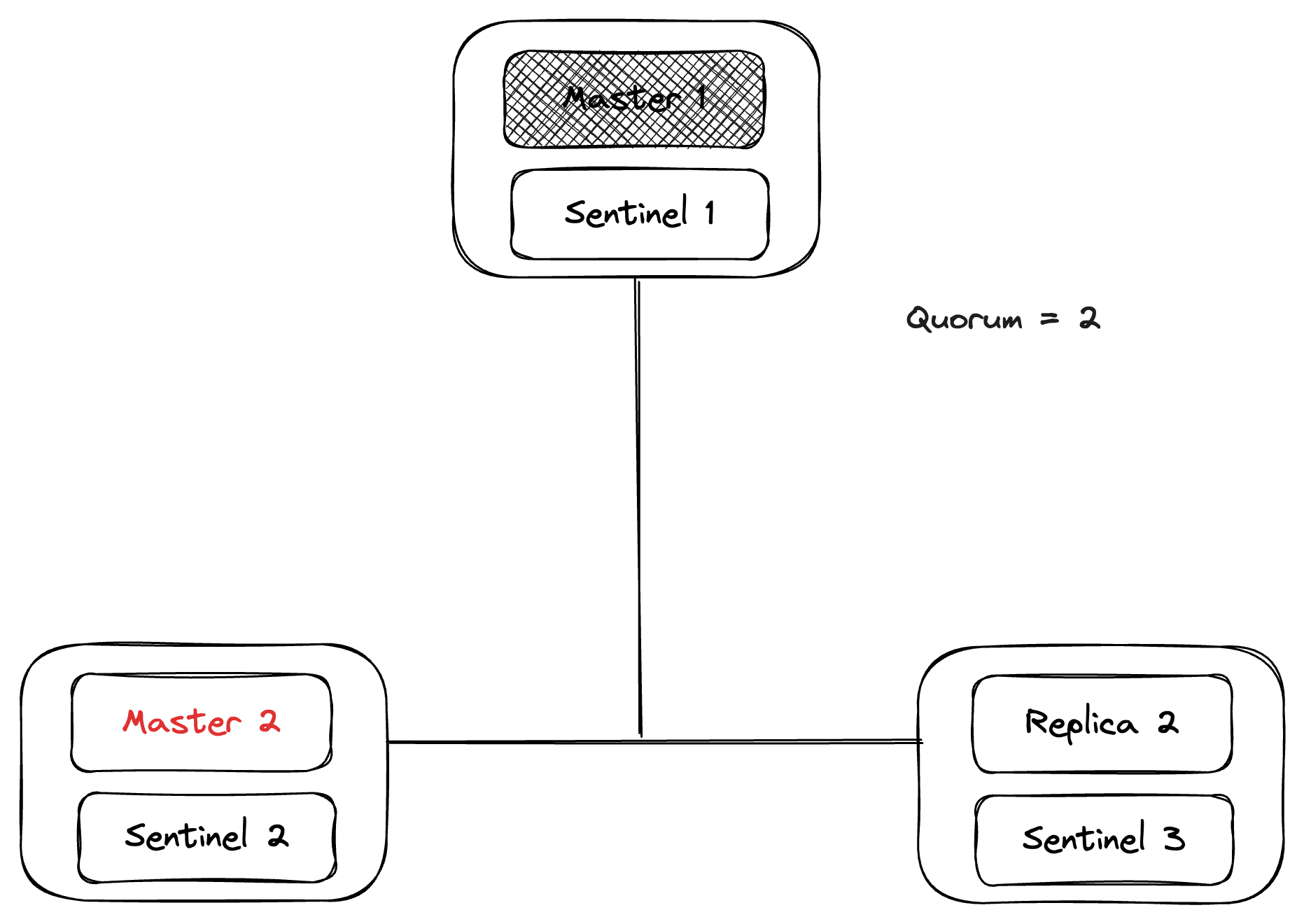
And, when the old master (Master 1) comes back online, sentinels sends the old master the new sentinel configuration. Then, the old master syncs the data from the new master (Master 2)and marks itself as a replica of the new master.
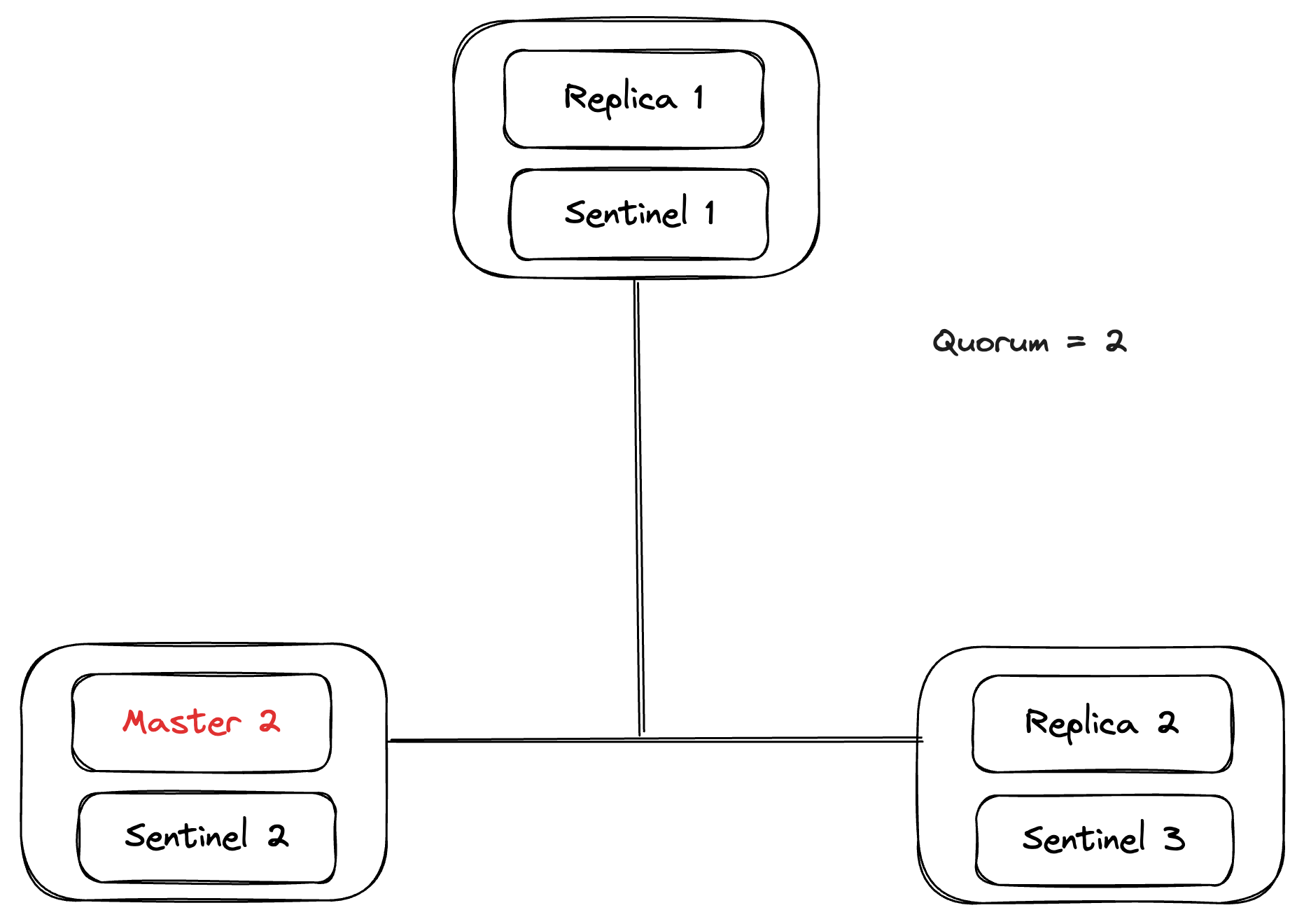
Quorum Election - Case II - Network Partition
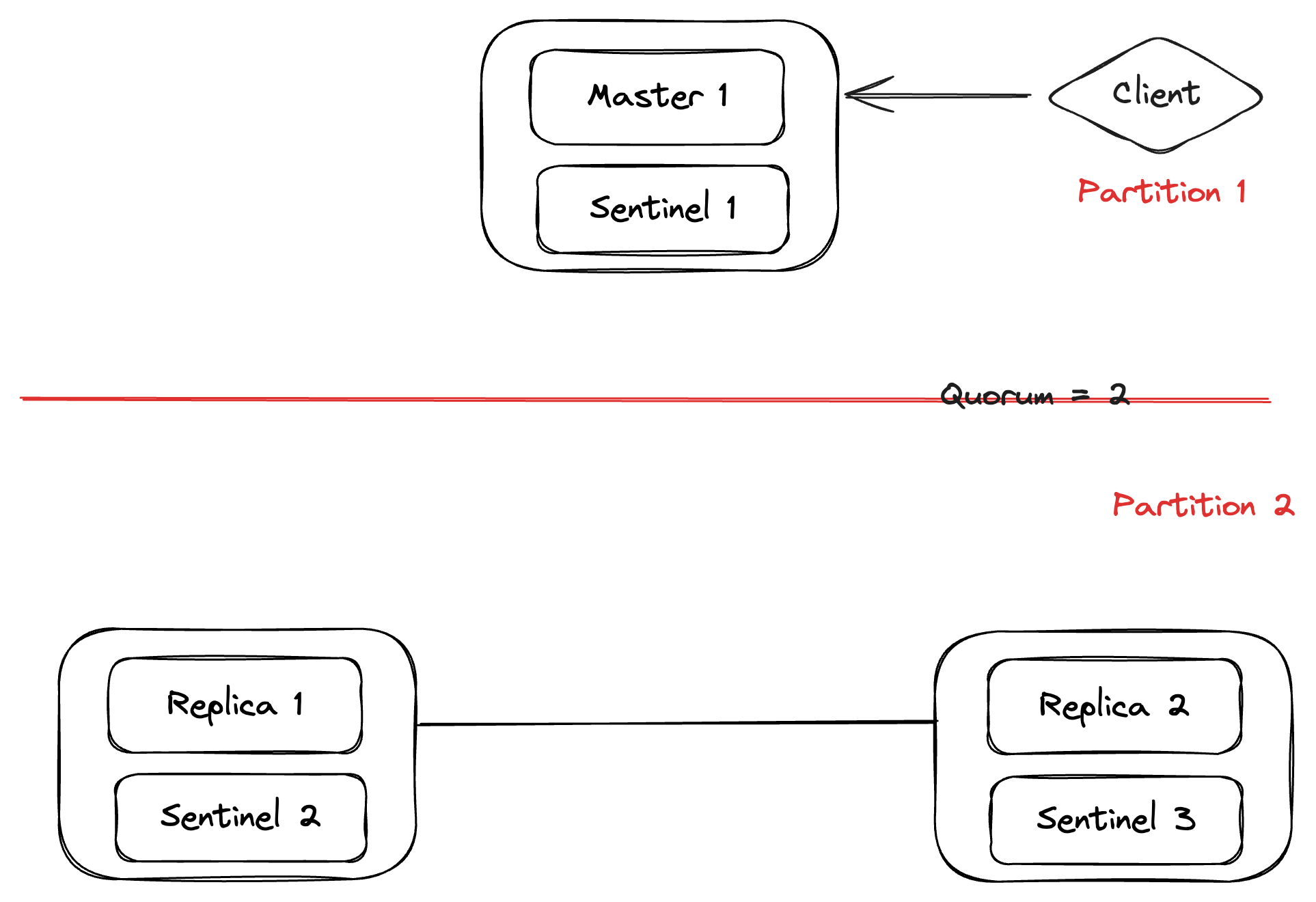
Let’s take a simple case where we have 3 Redis instances, running 3 sentinels, 1 master, and 2 replicas, with a quorum configuration set to 2.
Let’s say we have a network partition where Master 1, Client as well as Sentinel 1 are partitioned from the rest of the topology. Sentinel 2 / 3 will discover that Master 1 is down and agree on its failure. As the quorum config is set to 2 only, we only need 2 sentinel nodes to agree on the Master 1 being down and mark it as failing.
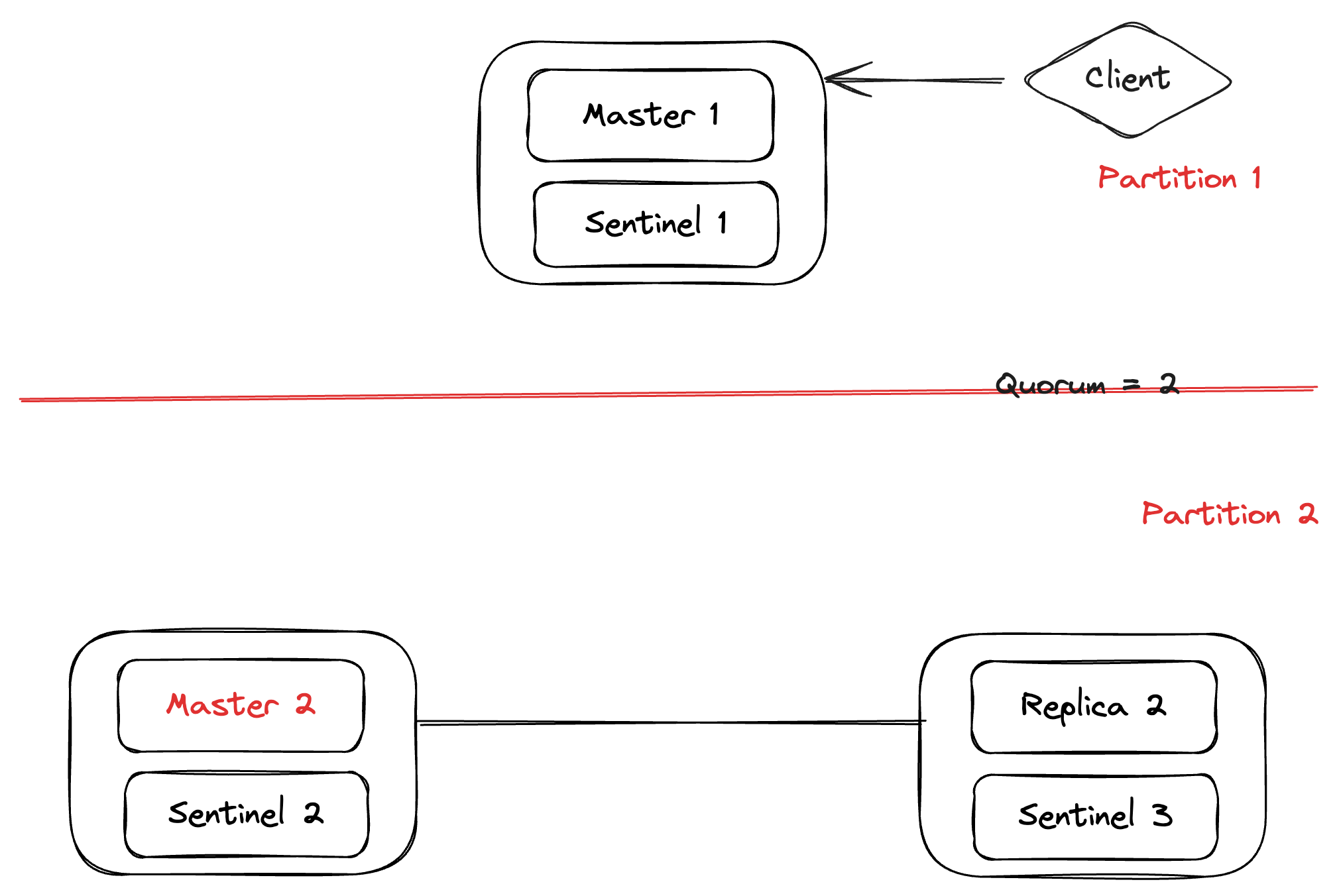
As Master 1 is missing from Partition 2 only, election and failover will be triggered in only Partition 2. After that, one of the two sentinels (Sentinel 2 and Sentinel 3) will be elected as leader by running an election among all reachable sentinels. A sentinel will be elected as leader only when the majority of the total sentinels in the cluster agree on it, which is 2 in this case, as both Sentinel 2 and Sentinel 3 will agree on Master 1 being down. After that, the elected sentinel will flip one of the replicas with the most recent commit (the sentinel tries its best to identify this replica, not always possible) to a new master and update the sentinel configuration. However, during this time, the Client might (depending on the configuration) continue to send WRITE traffic to Master 1 only, as it is doing the service discovery from Sentinel 1 only and Sentinel 1 only sees Master 1.
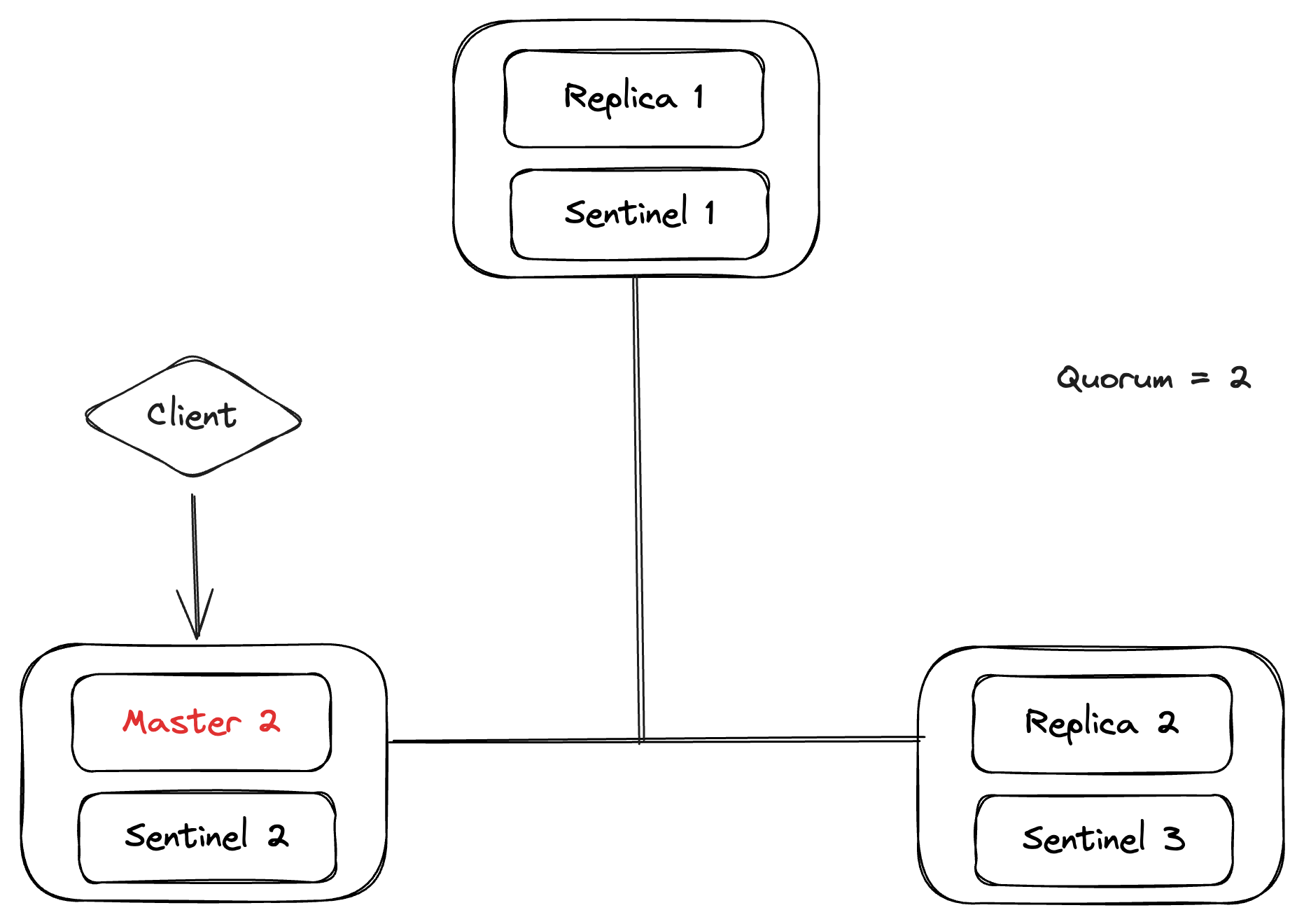
And, when the network partition is finished, sentinels send the old master (Master 1) with the new sentinel configuration. Then, the old master (Master 1) syncs the data from the new master (Master 2) and marks itself as a replica of the new master. As the Client now does the service discovery from Sentinel 1 which sees the new master (Master 2), it will start throwing the traffic to the new master. But, the WRITE operations that went to Master 1 while the network was in the partition will forever be lost.
That’s one of the reasons why Redis doesn’t provide any durability guarantees.
Redis Cluster
Redis scales horizontally with a deployment topology called Redis Cluster. Redis Cluster provides a way to automatically shard across multiple Redis nodes. It also helps with availability by flipping the replicas to master when the master is down.
Redis doesn’t use consistent hashing, but a different form of sharding where every key is conceptually part of what is called a hash slot.
Total Hash Slot = 16384
Hash (Key) = CRC16 (Key) % 16384
Let’s take an example of how it works end to end.
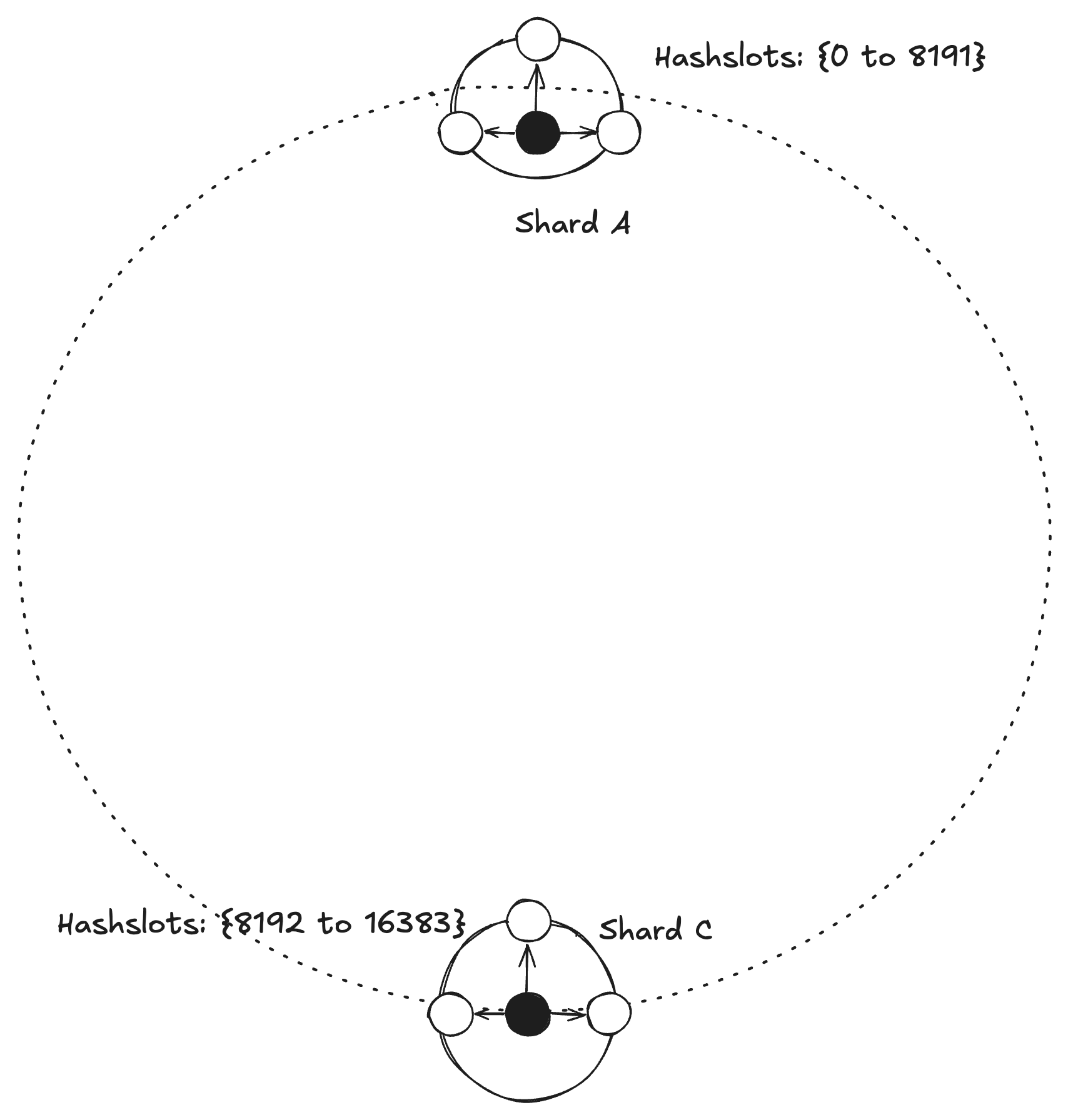
Here is the topology of three shards covering the total hash slot space. Each key belongs to one of the shards and one of the hash slot allocated to that shard.
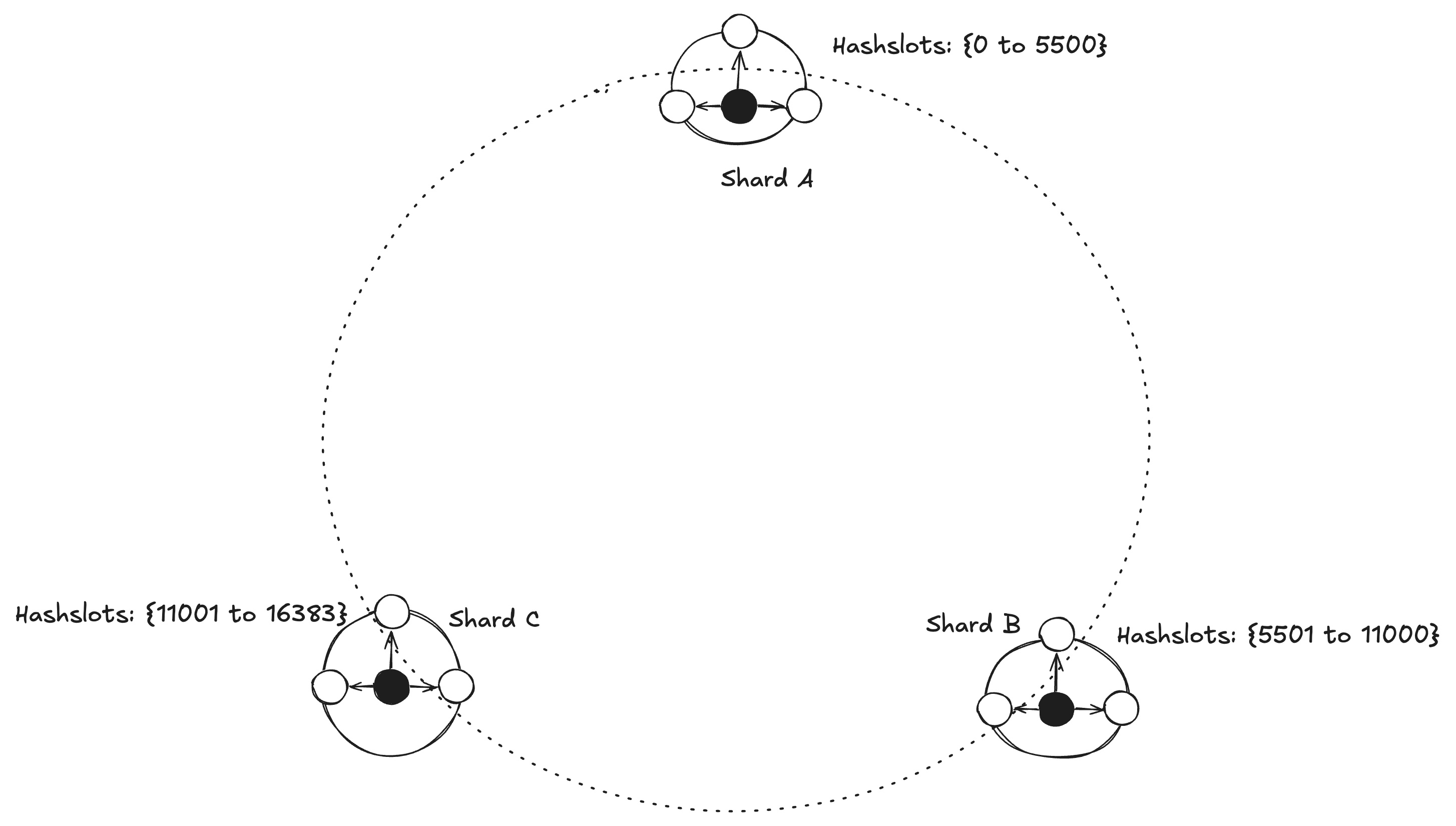
Adding a new shard Shard D will look like this, where the hash slots allocated to this new shard are assigned with a subset of each existing shard hash slot. There is also a config where you can choose how many hash slots one wants to transfer from a specific shard.
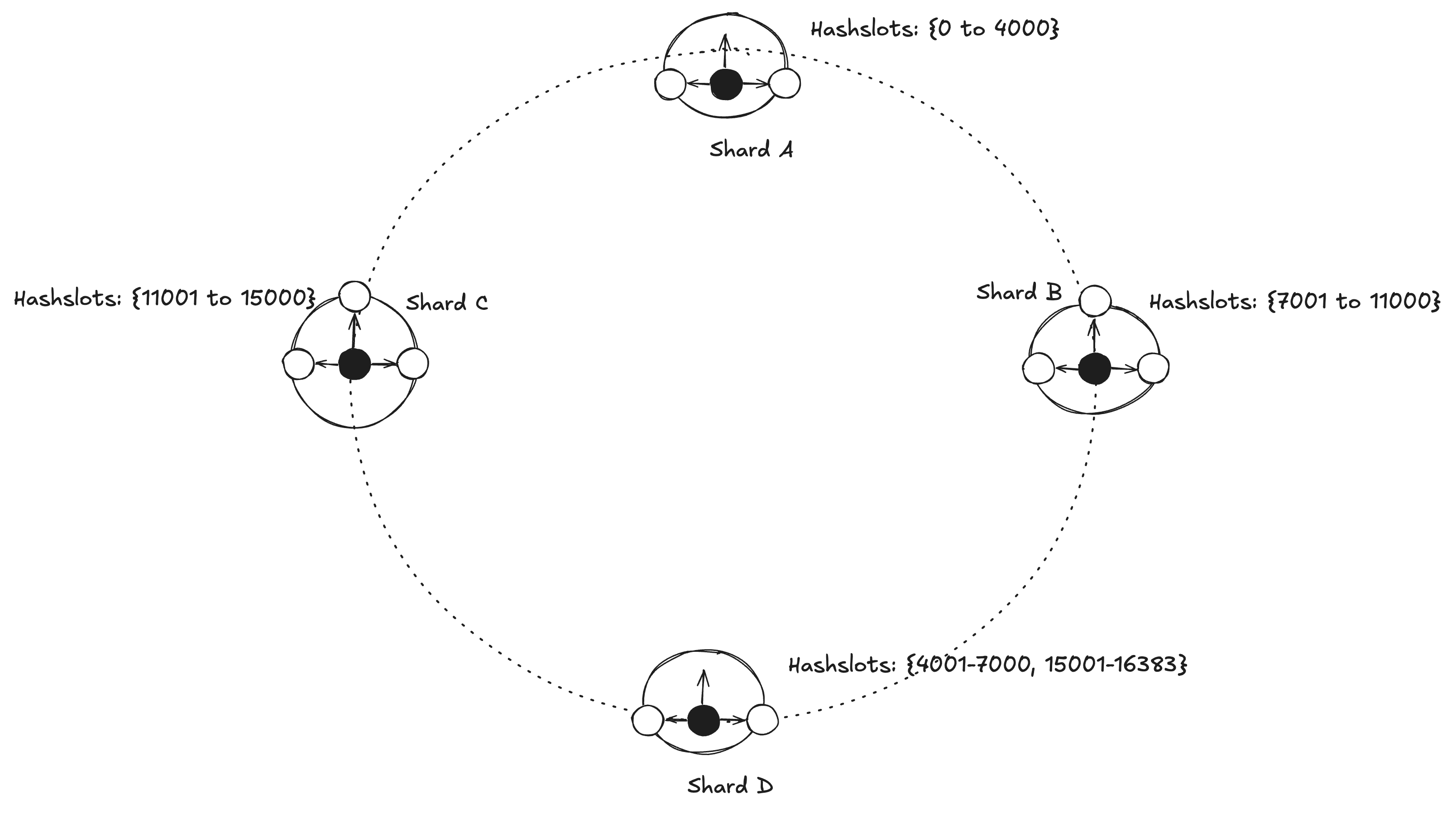
Similarly, for scaling down. If we have to remove Shard B, hash slots from Shard B will be split between Shard A and Shard B.
Caching Strategy
Trade-Offs
Availability
Redis uses the Master-Replica topology where a Replica can become Master if the Master is down or failed. This is automated in both Redis Sentinel and Redis Cluster.
Replication
Most of the use cases for Redis only need asynchronous replication to deliver the high availability that it promises. Although there are ways to make the replication synchronous by using the WAIT command. Although, the WAIT command doesn’t turn the system into a durable and/or strong consistent system, that depends on what persistence configuration is used in Redis and various other things as discussed in the Consistency section below.
Let’s take an example, to explain how the replication works. Each node has two data.
Replication ID, offset
Replication ID is composed of two things, Main ID and Secondary ID. Each of these IDs is a unique pseudo-random string. Every time an instance restarts from scratch as a master or a replica is promoted to master, a new Replication ID is generated for this instance. The replicas connected to a master will inherit its Replication ID after the handshake. So two instances with the same ID are related by the fact that they hold the same data, but potentially at a different time. It is the offset that works as a logical time to understand, for a given history (Replication Id), who holds the most updated data set.
As instance starts from scratch as master, the Secondary ID is null and the Main ID is assigned some pseudo-random string. Offset might be different at different replicas as replication is asynchronous.

If the master goes down, one of the replicas will become the new master and do the following
Secondary Id = Main Id
Main Id = new unique pseudo-random string
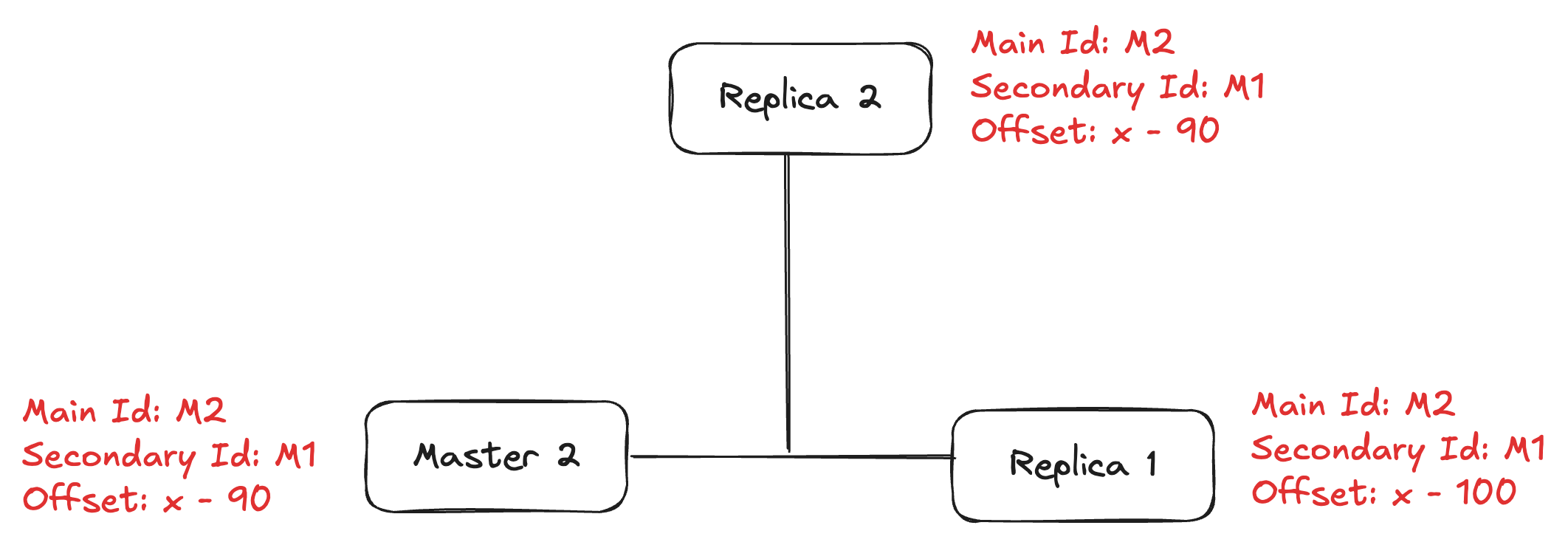
And then Replica 1 tries to PSYNC from the new master Master 2, sending its last state as
Replication ID = M1
Offset = x-100
This will tell the Master 2 node to check if the Replication ID is either equal to the Secondary ID or Main ID, it has to do partial data sync, and if it’s not equal to either of them, then it sends the full data sync to the Replica 1. Replica 1 will also inherit the Replication ID and offset from the new master.
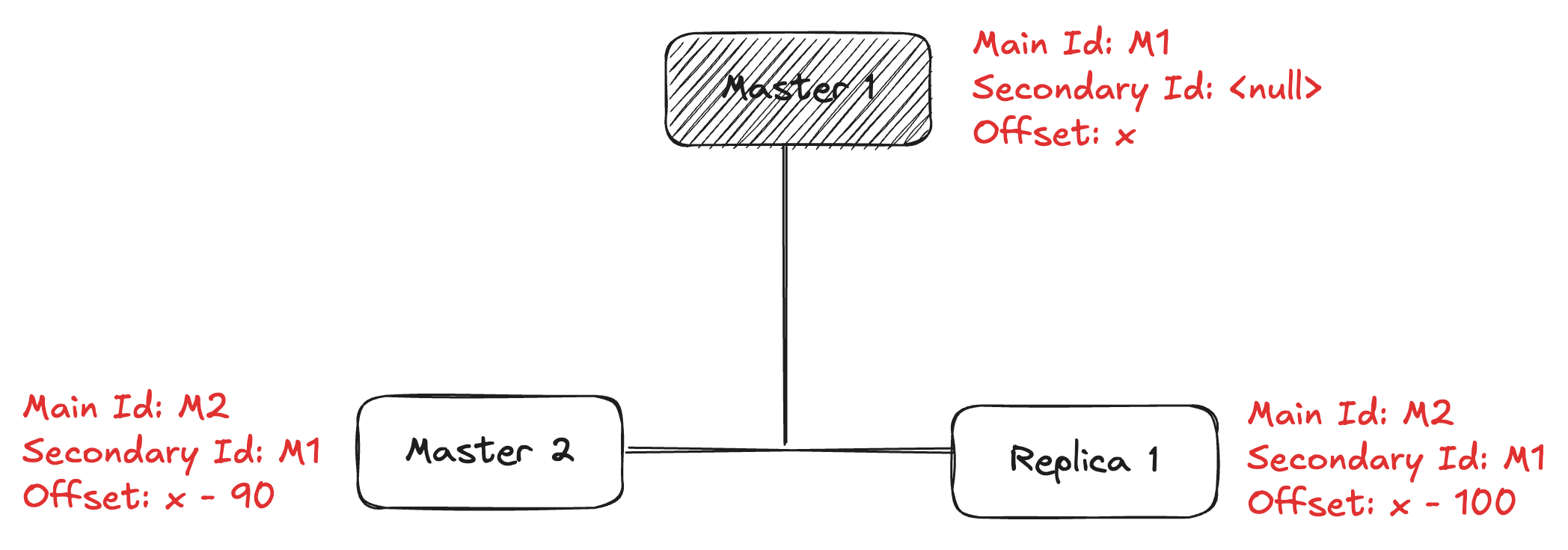
After the Master 1 comes back online, it syncs with the Master 2 sending its last state as
Replication ID = M1
Offset = x
As M1 is equal to the Secondary ID at Master 2, it will do partial data sync to the old master as well as mark the old master as Replica 2 and inherit the Replication ID and offset from the new master.
Note: We will ignore WRITABLE REPLICAS for this blog, as that is a deprecated feature and only exists for a historical reason and backward compatibility.
Scalability
Redis Sentinel is linearly scalable for reads but not for writes as it follows Single Master Multiple Replica topology.
Redis Cluster is linearly scalable for reads as well as writes as it follows the automatic sharding topology, where it can scale up and down according to the traffic for reads and writes independently.
Consistency
Redis Sentinel
Redis sentinel configurations are eventually consistent, so every partition will converge to the higher configuration available. Here, eventual consistency doesn’t mean it will not lose the data, eventual consistency means, all nodes will see the same commits in the same order to reach the same state. It does not guarantee to have all the commits that clients got ack’ed for, but RSM (Replicated State Machine) will be consistent across the nodes.
Few major reasons for the eventual consistency here :-
- Asynchronous replication
- Missing consensus on total order
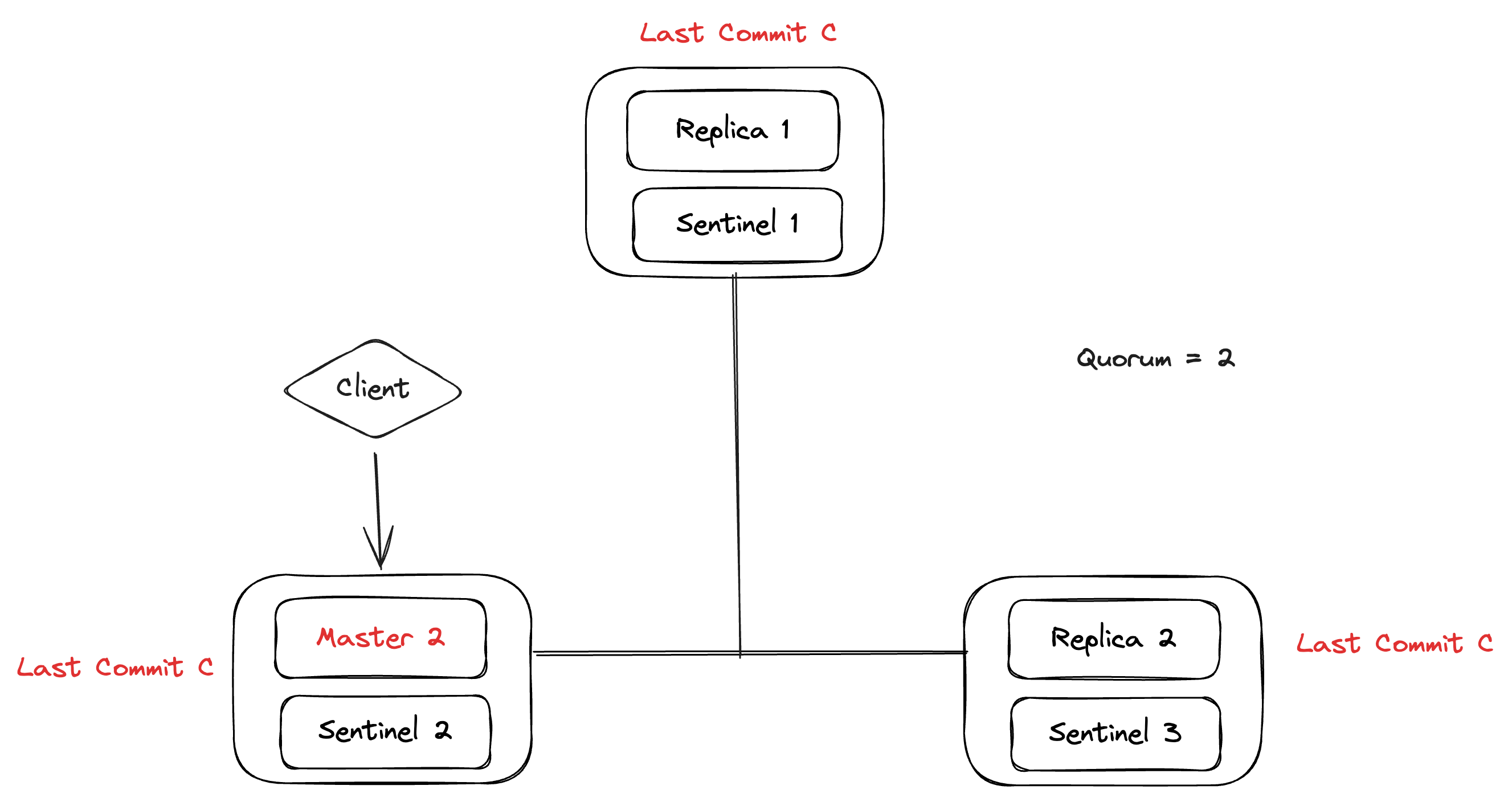
Let’s take an example to explain the issue here. Consider the following setup, 3 masters, 3 sentinels. As the replication is asynchronous, the Client will get the Ack for the commit C+1 before the replication is done.
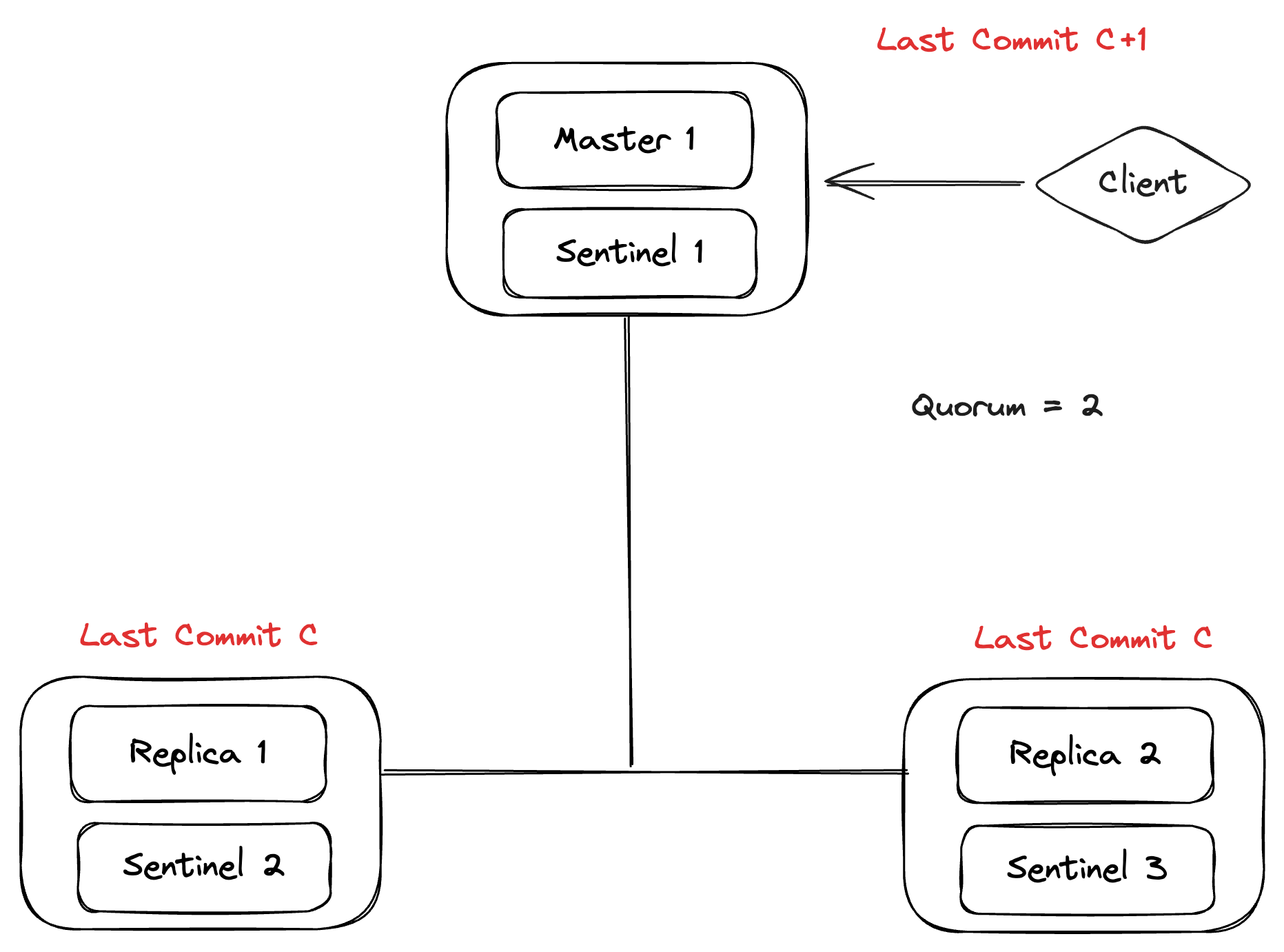
Let’s say a network partition happens and Partition 2 has the majority but the old commit C. Here, the client is still seeing the last commit as C+1.
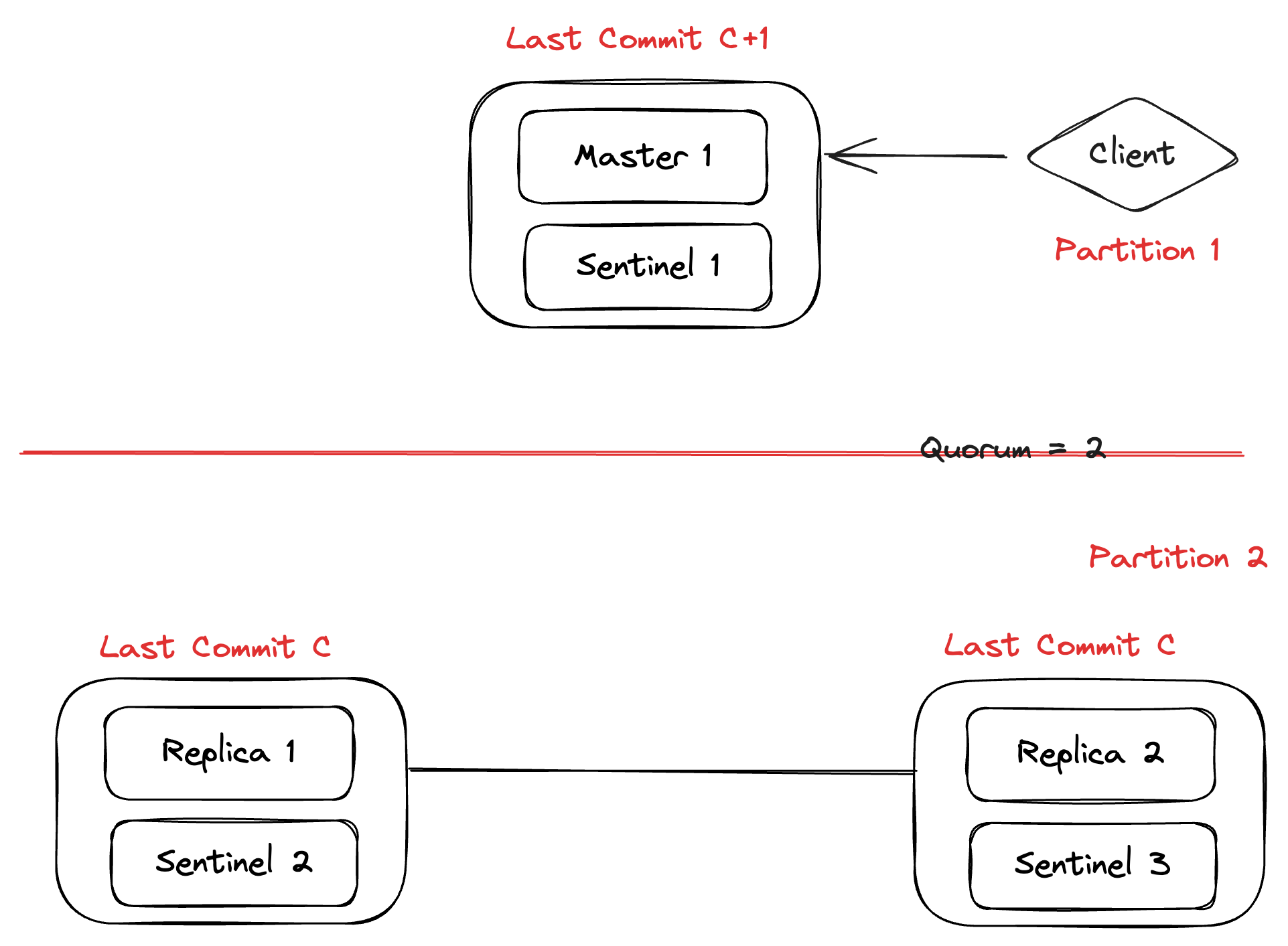
After the elections conducted by sentinels in Partition 2, Replica 1 will be converted to Master 2 which only has commit C, this means the state of the system has reverted to commit C and we have lost the commit C+1, making the system non-durable.
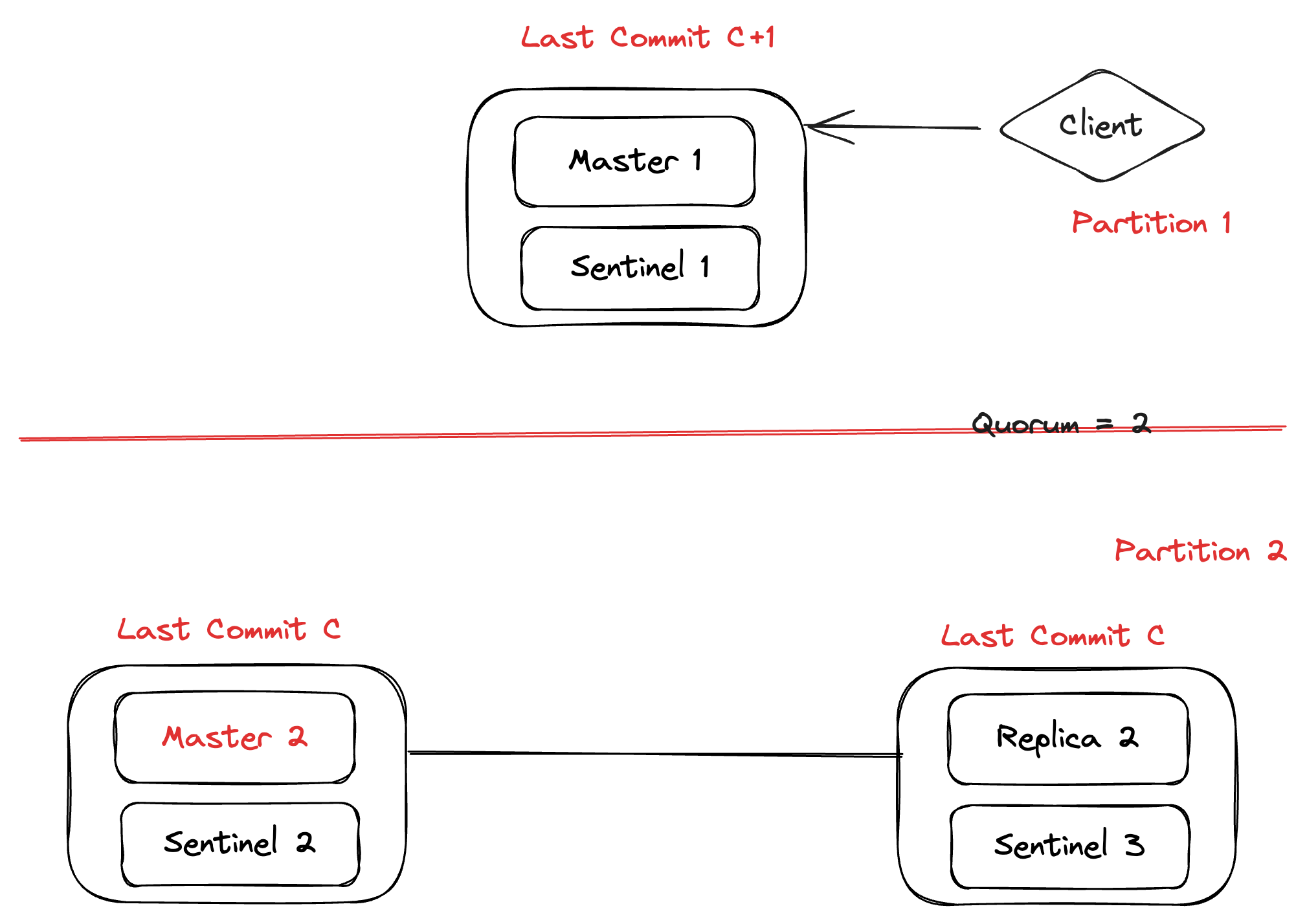
And, when the network partition is finished, sentinels send the old master (Master 1) with the new sentinel configuration. Then, the old master (Master 1) syncs the data from the new master (Master 2) and marks itself as a replica of the new master, completely losing commit C+1 from the system.
Redis Cluster
Redis cluster doesn’t guarantee strong consistency. The reasons are very similar to Redis Sentinel as mentioned above.
Few major reasons for the eventual consistency here -
- Asynchronous replication
- Missing consensus on total order
We can overcome [1] with synchronous replication which is available with WAIT command but not [2].
A new master node with no assigned hash slot can’t participate in the election process when a replica wants to become a master.
Persistence
There are three types of persistence that Redis supports.
- RDB - Redis Database
- AOF - Append Only File
- RDB + AOF
Each has its advantages and disadvantages which can be found here.
Generally, it is recommended to use option 3, both persistence methods, as it gives both data safety and recoverability.
Redis also supports AOF file data compaction using the BGREWRITEAOF command.
Limitations
Thundering Herd Problem
One of the major problems in distributed cache is the Thundering Herd Problem. When multiple clients try to get the cached value corresponding to a key and get cache-miss, all of them will rush to get the value from the main source (service or database). This can cause a thundering herd problem as the main source (service or database) could get overwhelmed with so many requests. The same situation can occur when we hit cache-expire.
Strategy I - Never Invalidate Cache
One solution is to never invalidate the cache as some data are always valid. We can also use some eviction algorithms like LRU (Least Recently Used) to clean up memory if/when required. But this solution only works for a subset of the cases and doesn’t work when data is invalid/old or when we hit cache-miss.
Strategy II - Mediator b/w Cache and Service
Another solution is to have a mediator sitting in the middle of the cache and service so that the mediator can de-duplicate the requests or act as a request queue and send only one request per key to the backend service. This solution is quite expensive to implement with engineering resources. Also, we will have to figure out how to group the queues so that we don’t cause Resource Starvation Problems, handle the request timeouts, and handle the back-pressure problem with queuing the requests.
Strategy III - Use Distributed Locking On Multi-Master Cache
Another solution is to use a distributed locking mechanism on the key at the cache. Whoever gets the lock, will see that the cache is not present or expired, fetch the value and update it in the cache, and then release the lock. While this is happening, the rest of the clients are waiting on the lock for the key, and when they get the key, they will see the new value. The best distributed locking implementation suggested by Redis is Redlock discussed below has its problem with correctness.
Strategy IV - Update-on-Write
Another solution is to always update the cache when we do update, insert, and delete operations along with writing to the backend service. But this solution only works for a subset of the cases and doesn’t work when we hit cache-miss.
Strategy V - Use Distributed Locking On Single-Master Cache
As Redis is a single-threaded service, multiple requests can do GET on a key, but the request will be processed one by one on the cache. So the first request which gets executed can try to put a any value corresponding to the key lock::key, if not already present using SETNX operation with some TTL. And rest of the clients will see that it’s already present and will try again to get the lock and will only succeed after the TTL expiry. On the other hand, the original thread with go ahead and get the value from the backend and will update the cache and delete the key lock::key.
Here is the sequence diagram to show the locking mechanism.
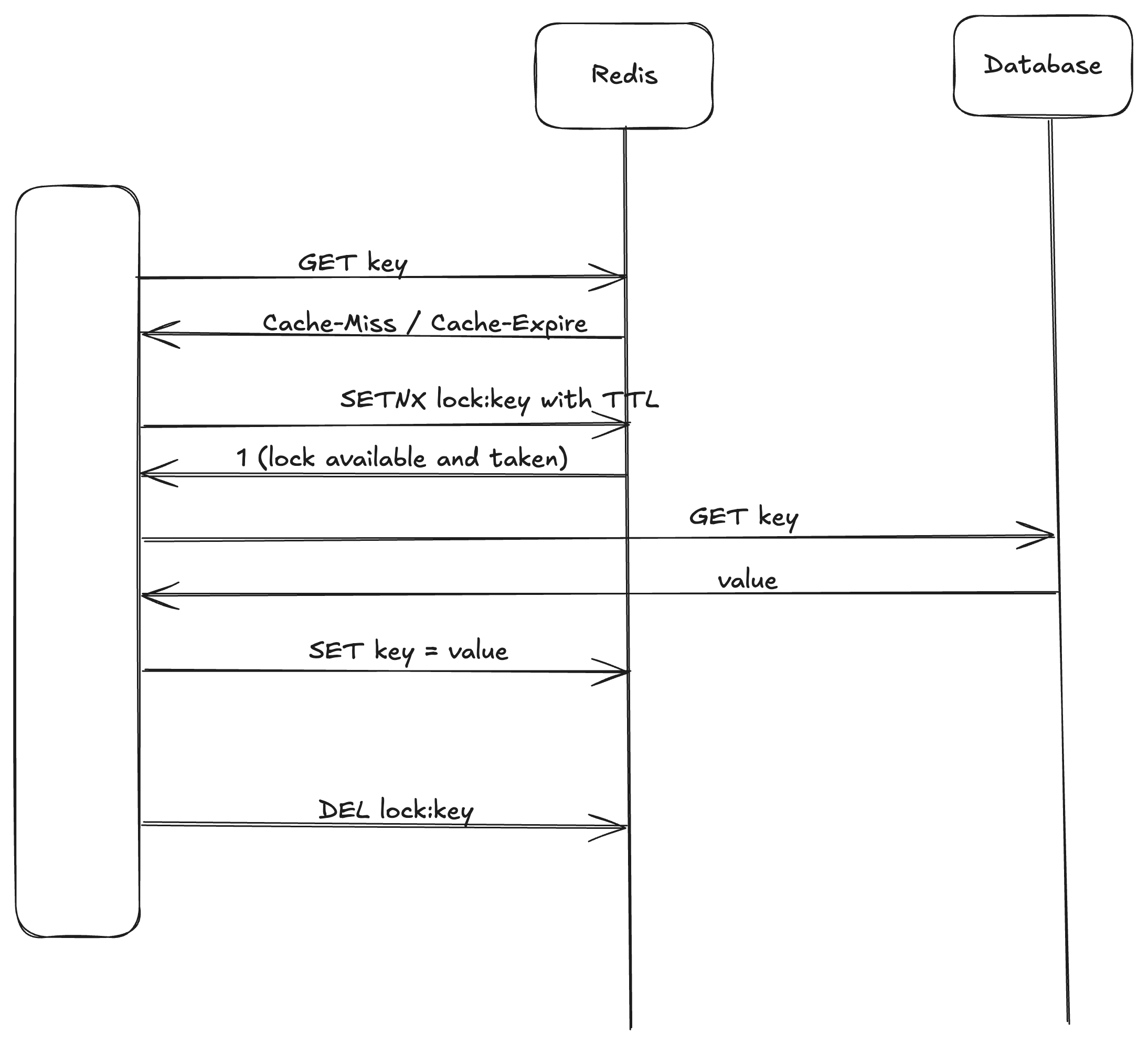
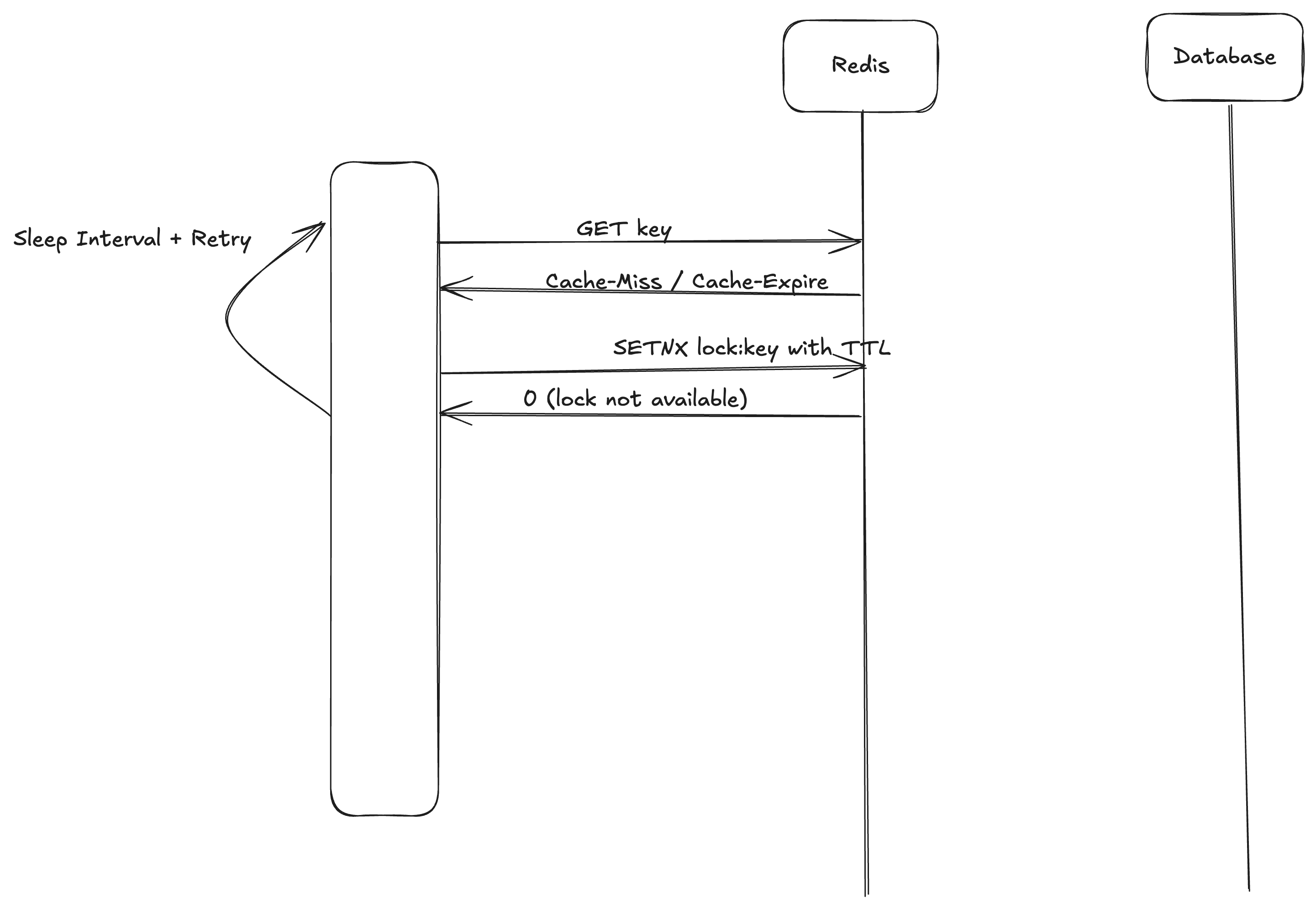
It’s a modification of MemoLock on the Redis blog. Modification is done to avoid the Starvation condition in the MemoLock as explained in the blog.
To avoid confusion, let me explain when the Starvation can occur.
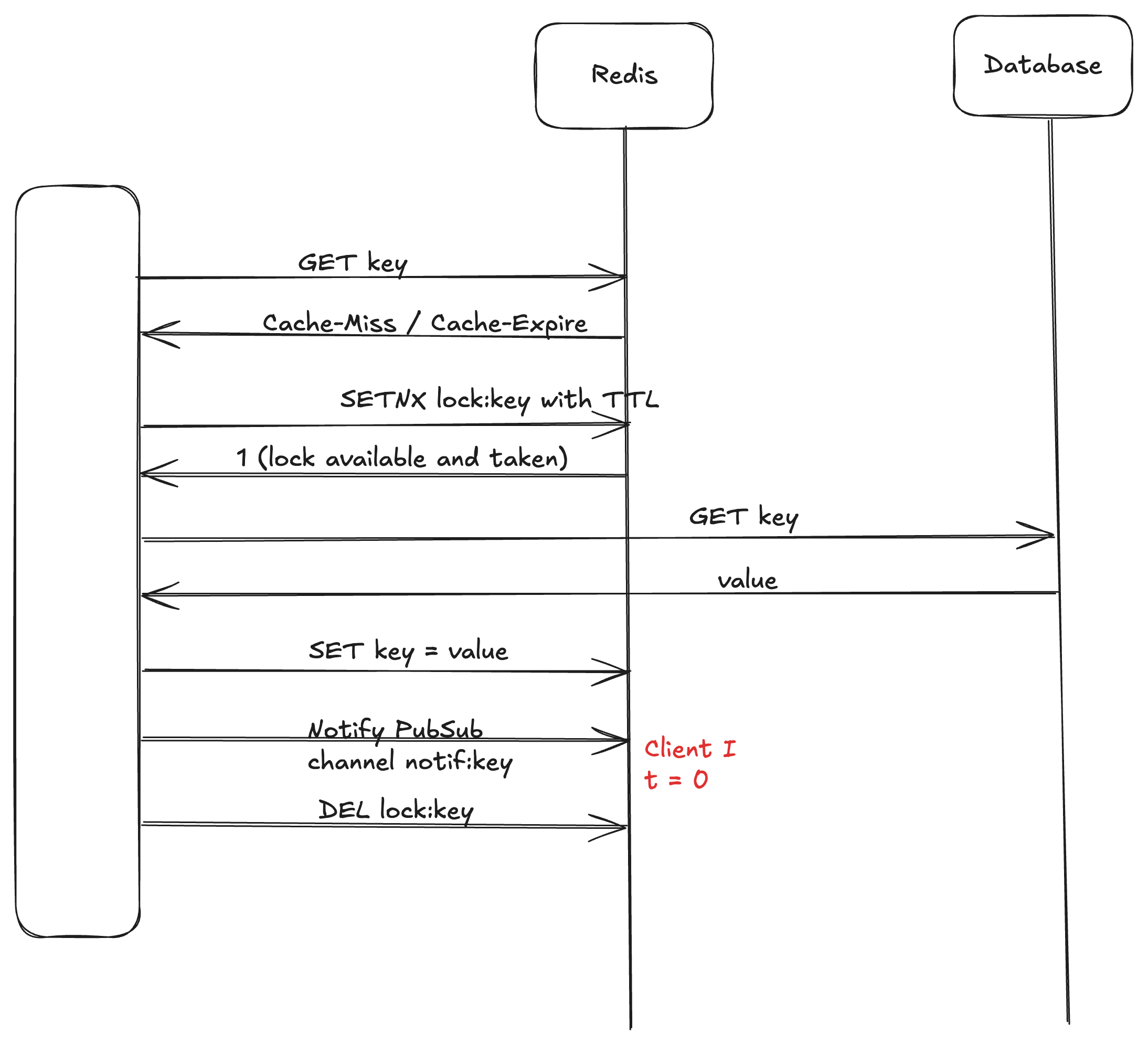
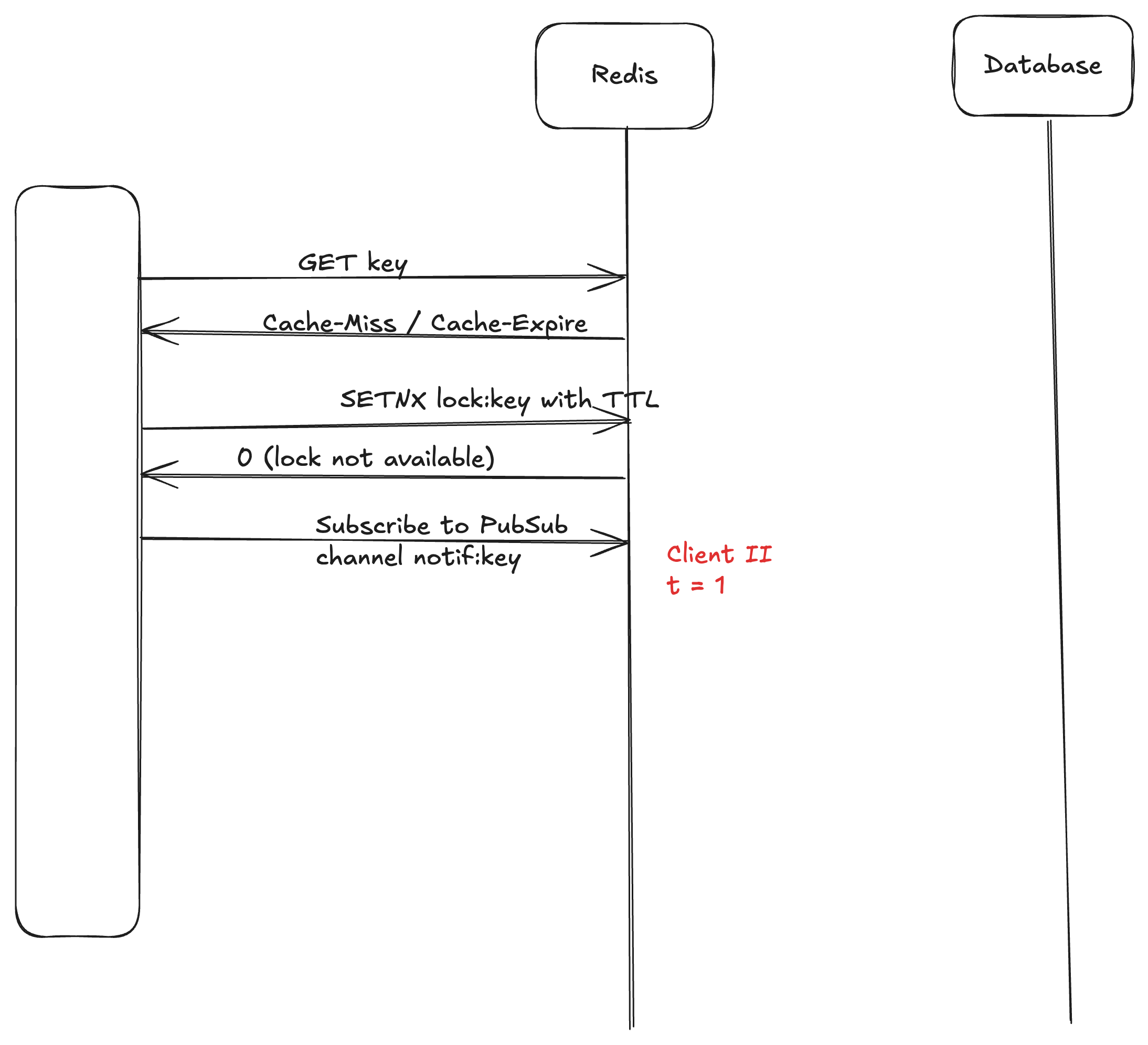
At t=0, Client I notifies the channel notif:key
At t=1, Client II subscribes to the channel notif:key
Here, at t=0 when the notification was sent Client II has not started listening to the channel. So, at t=1 when Client II starts listening to the channel, it will not see any message and will be blocked forever waiting for the message on the channel.
Another way to fix the problem with MemoLock is to have a timeout when listening to the channel and retry from the start after that.
Strategy VI - Use Distributed Consensus Framework
Best solution, for a distributed topology is to use a consensus frameworks like Zookeeper, ETCD or Consul.
Time Skew Problem
Redis Sentinel is heavily dependent on the instance time. It uses the time to calculate the various timeouts. But as we all know, in distributed systems, time is subjective and time skews are a constant thing. This might lead to sentinels behaving in unexpected ways.
This problem is nothing new in distributed systems and is very hard to solve. But, what we can do is identify such a situation with more probability. The way Redis does this is to use a timer that runs 10 times every 1 second and notes the timestamp. Redis goes into TILT mode if it sees that the delta between two consecutive timestamps is unexpectedly big or negative. Here are the conditions when Redis goes into TILT mode.
1. Tn - Tn-1 < 0
2. Tn - Tn-1 > 2000ms
When, in TILT mode the node marks itself as down, still continuing to monitor itself in case it gets out of the time skew to come back to a healthy state and self-heal.
Split Brain Problem
Problem 1 - Sentinel Scale Up
If you need to add multiple Sentinels at once, it is suggested to add it one after the other, waiting for all the other Sentinels to already know about the first one before adding the next. This is useful in order to still guarantee that the majority can be achieved only on one side of a partition, in the chance failures should happen in the process of adding new Sentinels.
This can be easily achieved by adding every new Sentinel with a 30-second delay and during the absence of network partitions.
Let’s take a look at a specific case where the wrong scale-up deployment of sentinel can cause Split Brain problems.
We have Sentinels all agreed on the total visible sentinels in the cluster to be 5.
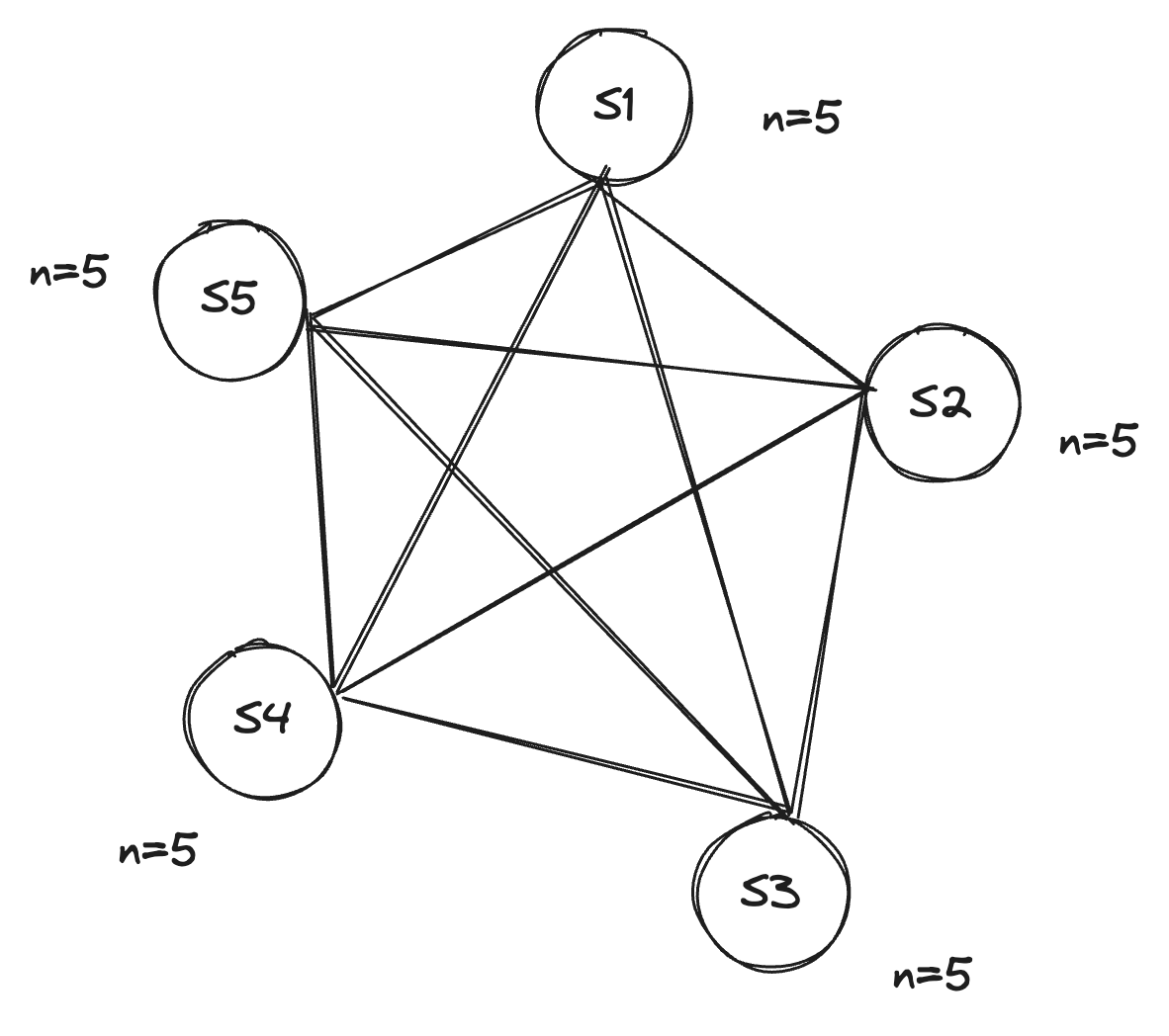
Now, let’s say 2 Sentinels, S6 and S7 want to join the clusters and are brought up at the same time.
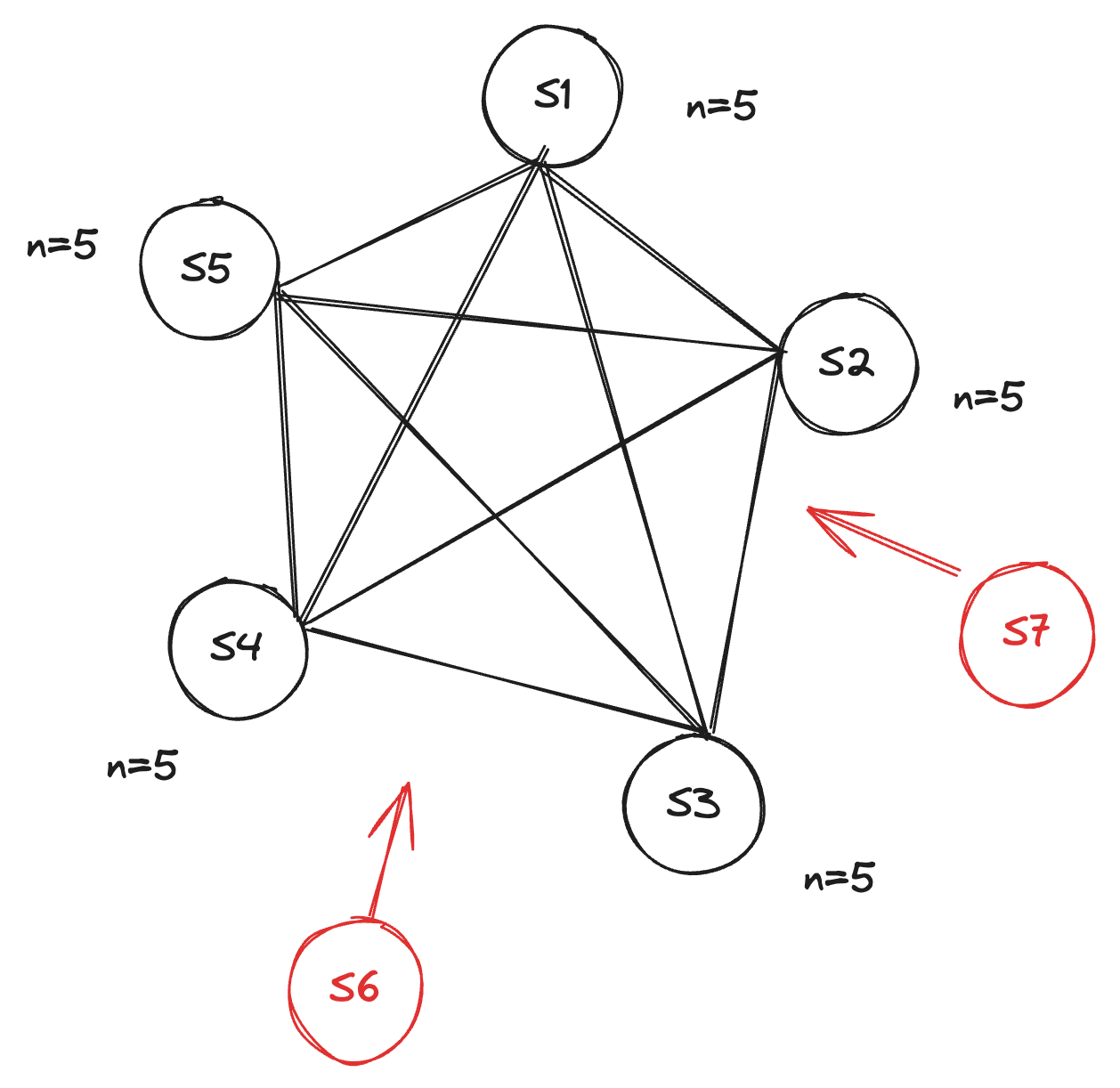
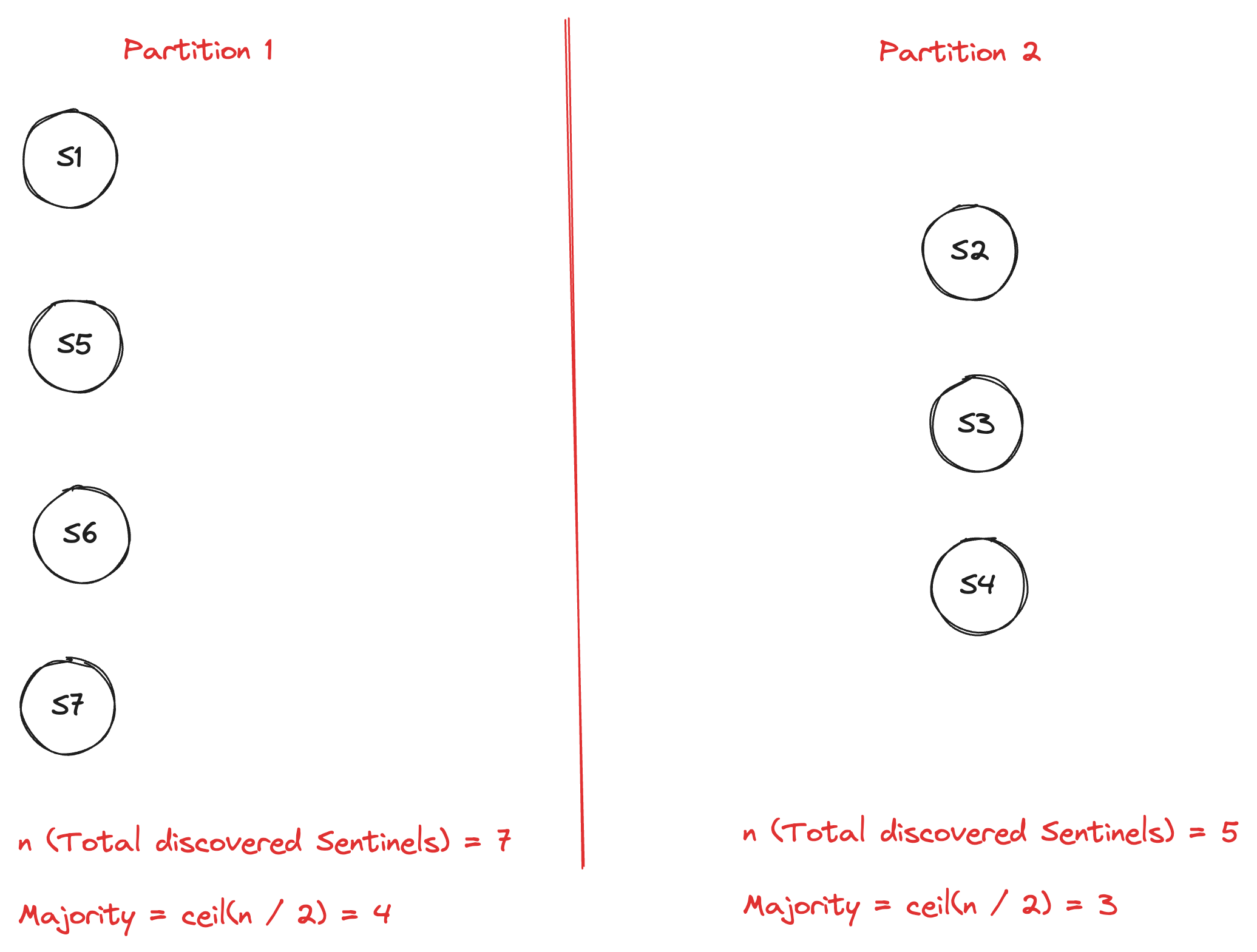
What this can cause is a split-brain situation like this, if the network partition happens during the scale-up. Let’s say a network partition happens and two partitions are created, Partition 1 and Partition 2.
`Partition 1` = {`S1`, `S5`, `S6`, `S7`}
`Partition 2` = {`S2`, `S3`, `S4`}
Here, the nodes in Partition 1 will see the total discovered sentinels to be 7, which makes the majority to be 4, which this partition can achieve. If a particular partition can achieve a majority then it can take decisions on its own for Redis.
Similarly, Partition 2 will see the total discovered sentinels to be 5, which makes the majority to be 3, which this partition can achieve. If a particular partition can achieve a majority then it can take decisions on its own for redis.
Now, in a cluster, if two subclusters can make their own decision for Redis, it will result in a split-brain situation.
As a solution to this problem, Redis suggests scaling up sentinels one by one. Make sure to run SENTINEL MASTER after every sentinel addition to make sure all nodes agree on the same number of sentinels.
Problem 2 - Sentinel Scale Down
Removal of sentinel nodes is also recommended to be done one by one to avoid the same situation of Split Brain as scaling up, mentioned above.
The protocol that Redis has does not handle the Split Brain situation very well.
Distributed Lock
Redlock
Dr. Martin Kleppmann wrote a very nice blog[11] in 2016 where he analyzes the validity of the Redlock algorithm and concludes this.
I think the Redlock algorithm is a poor choice because it is “neither fish nor fowl”: it is unnecessarily heavyweight and expensive for efficiency-optimization locks, but it is not sufficiently safe for situations in which correctness depends on the lock.
In particular, the algorithm makes dangerous assumptions about timing and system clocks (essentially assuming a synchronous system with bounded network delay and bounded execution time for operations), and it violates safety properties if those assumptions are not met. Moreover, it lacks a facility for generating fencing tokens (which protect a system against long delays in the network or in paused processes).
On the other hand, if you need locks for correctness, please don’t use Redlock. Instead, please use a proper consensus system such as ZooKeeper, probably via one of the Curator recipes that implements a lock. (At the very least, use a database with reasonable transactional guarantees.) And please enforce the use of fencing tokens on all resource accesses under the lock._”
He instead suggests to use other solutions like:-
- Straightforward single-node locking algorithm for Redis.
- Zookeeper with curator recipes.
The bottom line is that Redlock doesn’t work for the guarantee this system needs.
Best Practices
[BP.1] You need at least three Sentinel instances for a robust deployment.
[BP.2] Deploy at least three Sentinels in three different boxes.
[BP.3] Add/Remove sentinels one by one to not reach split-brain situation.
[BP.4] Have persistence turned ON for the master and replicas to avoid complete data loss in case of auto-restart enabled for master nodes.
Summary
To conclude this blog, we need to answer the problem statement mentioned in the Introduction.
Can we use any Distributed Cache to cache the data?
Yes, we can. But, there are trade-offs. Redis is inherently a highly available and partition-tolerant system and is designed specifically for read-heavy systems. It provides no guarantee of the durability of data as data losses are highly possible. Redis in its raw form is not the right system to use if you are looking for strict consistency for the data, although it works incredibly well for eventually consistent data.
Also, be wary of its limitations like time skew, split brain, and thundering herd.
References
Redis Security Management - https://redis.io/docs/latest/operate/oss_and_stack/management/security/
Redis Sentinal - https://redis.io/docs/latest/operate/oss_and_stack/management/sentinel
Redis Replication - https://redis.io/docs/latest/operate/oss_and_stack/management/replication/
Redis Cluster Scalability - https://redis.io/docs/latest/operate/oss_and_stack/management/scaling/
Excalidraw Diagram - https://excalidraw.com/#json=EdnzpnTa-7-vxhqS8Wcbk,42SWf1ZoHLTS_y5QmlykPQ
Redis Persistence - https://redis.io/docs/latest/operate/oss_and_stack/management/persistence/
Data Compaction - https://docs.cloudera.com/cdw-runtime/cloud/managing-hive/topics/hive_hive_data_compaction.html
Instagram Engineering - Thundering Herd - https://instagram-engineering.com/thundering-herds-promises-82191c8af57d
TTL Hell - https://calpaterson.com/ttl-hell.html
MemoLock - https://redis.io/blog/caches-promises-locks/
How to do distributed locking - https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
Eventual Consistency - https://www.allthingsdistributed.com/2008/12/eventually_consistent.html
ETCD (RAFT) - https://etcd.io/
Apache Zookeeper (ZAB) - https://zookeeper.apache.org/